While many dismiss macro as too sparse for AI, this research reveals how purpose-built machine learning is unlocking the potential for alpha where others see limits—turning local signals into global insights, and complexity into clarity.
Underestimated Edge: How Machine Learning Is Enhancing Macro Investing

Key points
01.
Pooling macro data seeks to boost forecast precision
By combining macro signals across countries and markets, machine learning models learn faster and adapt better to regime shifts— providing advantages over traditional time-series methods, especially when signals are sparse or structurally fragile.
02.
Turning local signals into potential sources of global alpha
Machine learning seeks to transform complex local datasets—like foot traffic or regional GDP—into tradable macro exposures. Using AI-driven mapping tools, investors may have new opportunities to harness granular economic insights in global portfolios.
03.
Ranking over predicting: a macro strategy view
In relative value investing, learn-to-rank models may offer advantages over traditional regressions. These machine learning techniques have shown strength in ranking assets by expected return, with the potential for more consistent performance in volatile, low-breadth macro environments.
Reframing machine learning in macro investing
Machine learning has reshaped many corners of the investment landscape—especially in fast-moving, high-breadth arenas like equity and credit security selection. Yet in macro investing, its impact has been more muted. The challenge? Macro markets have fewer distinct return streams to model, making it harder to apply traditional machine learning techniques effectively.
Too often, naive applications of machine learning in macro investing gravitate toward a narrow set of dominant factors. This overconcentration can lead to overfitting, reducing robustness and limiting practical deployment. As a result, many macro hedge funds have approached machine learning cautiously, often reserving it for small, ancillary roles, such as enhancing investment narratives rather than driving core decisions.
In contrast, machine learning has thrived in long/short equity and corporate bond strategies, where the breadth of instruments and insight variety is far greater.1 These successes have fueled significant investments in data infrastructure, computational resources, and modeling capabilities across quantitative investment platforms.2
At BlackRock, for instance, a single data store for alphas allows for modular applications of machine learning across diverse use cases. This foundation has now laid the groundwork to unlock machine learning’s potential in macro strategies.
A new path forward for machine learning in macro
Instead of forcing machine learning into the mold of direct return prediction for individual macro assets — a task fraught with statistical and practical challenges — we believe the key lies in reframing the problem. Our approach explores how machine learning may deliver value when tailored to the structural realities of macro: sparse signals, temporal fragility, and low asset granularity.
To overcome the limitations of traditional macro modeling, we highlight three key machine-learning applications that target the core constraints of low breadth, weak signal generalizability, and sparse data environments:
- Pooling macro assets and datasets to strengthen time-series models
- Translating complex macroeconomic insights into tradable asset exposures
- Deploying specialized learning techniques within relative value frameworks
While additional frontiers — such as those involving large language models — are the subject of a forthcoming white paper, this paper focuses on the foundational innovations already reshaping how macro strategies are built, tested, and scaled.
Pooling macro assets and datasets to strengthen time-series models
In macro investing, a meaningful edge comes not just in identifying signals, but from learning when and where those signals matter. Traditional time series models, trained in isolation, often suffer from sparse data, structural breaks, and limited ability to adapt across regimes.3 Machine learning offers a more powerful approach: pooling data across countries, assets, and markets to train regularized models that extract shared patterns and boost robustness.
One example is our approach to directional beta timing. By training a model on a cross-sectional library of macro signals, and imposing a non-negative constraint, the model can systematically weight signals in ways that may improve return prediction over time.
The practical power of this method was clearly demonstrated in our duration timing model during the post-Covid inflation regime. The pooled model swiftly adapted by significantly upweighting inflation-sensitive signals outperforming both
- Univariate time-series models, which lagged in recognizing the regime shift
- Naïve 1/N signal approaches, which lacked adaptability
Importantly, the pooled model’s larger signal weight variation isn’t just noise – it corresponded to rising information coefficients across the board, confirming strong predictive value.
Figure 1
Source: BlackRock Systematic, with data from Aladdin, Bloomberg, Price Stats, Thomson Reuters. Signal weights are rescaled to sum to 100% at each point in time. The orange line shows the relative signal weights attributed to inflation signals from fitting a rolling five-year elastic net regression on a single univariate target, averaged across each market. The pink line shows the same relative signal weights from fitting a pooled elastic net regression on all targets simultaneously. Calculated as of May 2025.
In Figure 1 above, the top chart shows relative signal weights to inflation insights in our duration timing model for a naïve 1/N benchmark in orange, learned weights from univariate regressions averaged across DM bond future universe in yellow, and the pooled learner’s weights in pink. The bottom chart shows our cumulative duration timing signal returns scaled to 1% risk for the three approaches.
This pooling-based approach reframes macro signal timing into a systematic, scalable, and forward-looking process. Rather than being constrained by the narrow histories of individual markets, machine learning can tap into the empirical breadth of the global macro landscape, elevating the potential that investors can detect and respond to structural shifts with agility and precision.
Translating complex macroeconomic insights into tradable asset exposures
A core challenge in macro investing lies in bridging the gap between rich, high-dimensional datasets and tradeable macro instruments. Many macroeconomic signals, especially geospatial or local economic indicators, hold valuable insights, but are difficult to map to investable asset classes in a consistent, scalable way.
Advances in machine learning and AI techniques are helping solve this problem. Through automated, robust mapping frameworks, we can now extract investment signals from complex, previously underutilized datasets and systematically link them to baskets of tradable securities. We illustrate this through two applied use cases in our macro strategies:
Mapping points of interest to tradable equity exposures
In our research processes, we've leveraged hyper-local geospatial data– such as foot-traffic, extreme weather events, and measures of local economic activity – as novel alpha signals.4 The key challenge? Understanding which securities are most exposed to these localized impulses.
This goes beyond tracking companies solely by their headquarters—across the U.S. large-cap equity universe, approximately 80% of a company's footprint, as measured by location presence, is situated outside its home state.5
To tackle this, we developed an AI-driven mapping system using Points of Interest (POI) data- defined by precise longitude-latitude coordinates of company physical locations globally. These POIs are linked to public companies and tradable exposures. We leverage both purchased and publicly available datasets that include one or more identifiers, such as company name, business type, or associated website. Then, we leverage machine learning techniques and AI to map to companies based on a ‘knowledge-graph’ of all known characteristics, leveraging known corporate subsidiary relationships, name matching, probabilistic techniques and artificial intelligence agents.
Figure 2: 1.8 million US company locations mapped to 8,750 tradeable companies
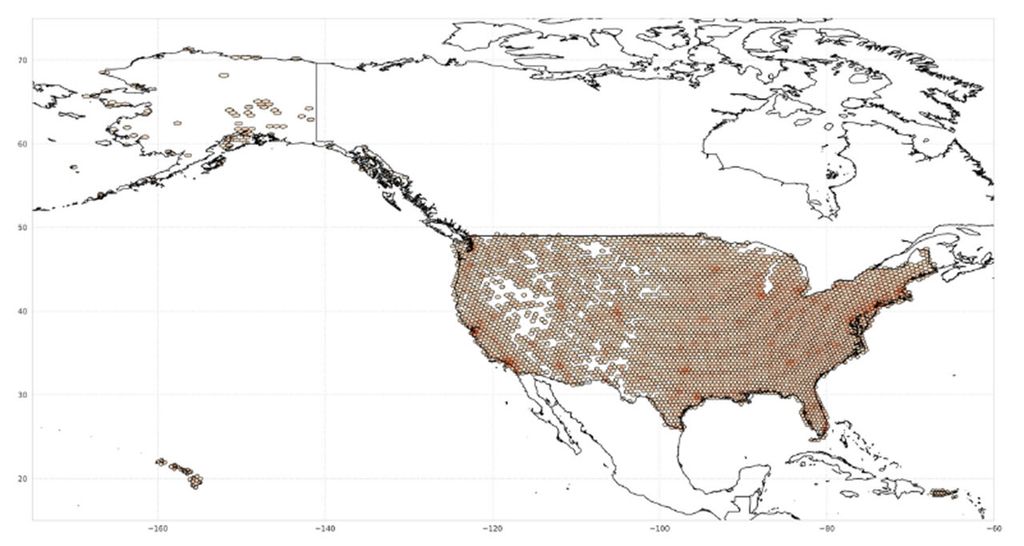
Source: Precisely, BlackRock. As of May 2025.
For example, (as shown in Figure 2) in North America, we've mapped over 1.8 million physical company locations to 8,750 publicly traded entities, enabling the construction of region-specific investment baskets, which are effectively tradable exposures mapped to hyper-local areas. For example, the co-movement between these state- or city-level baskets and the local GDP growth surprises, offers highly targeted macro expressions for our insights.
These techniques are turning formerly “hard-to-trade” macro insights into powerful components of systematic investment strategies. By automating the translation of economic information into investable exposures, we seek to enable a more responsive, nuanced, and data-rich approach to macro investing — one that adapts dynamically to regional shifts and localized disruptions.
Deploying specialized learning techniques within relative value frameworks
Traditional return methods in macro — most notably linear regression methods — have typically been designed to predict an individual asset’s returns. While effective in some settings, this approach is often misaligned with the goal of relative value (RV) investing, where the primary objective is not to predict precise return magnitudes, but rather rank a set of assets’ forecasted returns from best-to-worst. In this context, learn-to-rank methodologies — originally developed in the machine learning domain for recommendation systems and search engine optimization — offer a more applicable framework. These methods are designed to generate ranked outputs directly, making them especially well-suited to address RV investment problems.
Ranking G5 Sovereign Bonds with Macroeconomic Predictors
To illustrate the power of this approach, we examine a simple forecasting problem using two classical predictors of developed-market sovereign bond returns — Consumer Price Index (CPI) and GDP analyst revisions. As can be seen in the simulated backtests in Figure 3, these two measures have historically been robust predictors of bond futures returns but their explanatory power has diminished over the past decade due to evolving macroeconomic regimes.
We compare two distinct learning methods:
- Traditional multivariate linear regression Each G5 bond is modeled individually using multivariate regression, where the learner is trained on each asset’s 20-day returns using the two predictors. Forecasted returns are treated as alphas, which are then backtested to evaluate performance.
- Learn-to-rank “LambdaRank”6 Instead of predicting returns directly, the model learns to rank bonds at each point in time by comparing asset pairs. These rankings are then standardized using cross-sectional z-scores and evaluated through backtests to assess effectiveness.
Figure 3: Comparison of strategy performance simulation using alternate machine learning approaches in combining macroeconomic signals across bond returns
Source: Consensus Economics, BlackRock. For illustrative purposes only. As of June 30, 2025. The back-tested past performance returns are shown for illustrative purposes only and are not meant to be representative of actual performance returns of any account, portfolio or strategy. The back-tested performance period is from 01/01/2000. The back-tested performance returns are shown gross of all fees. If all fees and expenses were included, returns would be lower. The backtested performance returns reflect the reinvestment of all dividends interest and other income. The securities or asset classes in the back-tested portfolios were selected with the full benefit of hindsight, after their performance returns over the period shown was known. It is not likely that similar results could be achieved in the future. Back-tested performance returns have certain limitations. Unlike actual performance returns, they do not reflect actual trading, liquidity constraints, fees and other costs. Back-tested performance returns also assume that asset allocations would not have changed over time and in response to market conditions, which might have occurred if an actual account had been managed during the time period shown. No representation is being made that any account, portfolio or strategy will or is likely to achieve results similar to those shown.
The results are telling. While the linear regression model has been able to predict asset returns historically, its predictive power declines substantially along with the predictive power of the underlying features. In contrast, the learn-to-rank approach maintains stronger performance consistency, even in the face of macroeconomic regime changes and increased return volatility.
Why does this happen? As macro regimes shift, global factors dominate shrinking the idiosyncratic component of returns, making return magnitudes become harder to forecast--but relative rankings retain their relevance, even in low-breadth settings where macro assets are highly correlated and influenced by common global factors. Selecting an appropriate forecasting methodology tailored to the specific investment scenario is crucial. Direct return prediction via traditional regression may be suitable in stock selection contexts, characterized by numerous assets and significant idiosyncratic variation. Conversely, macroeconomic forecasting problems, which often involve fewer highly correlated assets influenced by dominant global factors, may benefit significantly from methodologies specifically designed to optimize relative rankings.
Fit-for-Purpose Machine Learning in Macro
Across all three examples, a common theme emerges: machine learning in macro must be purpose-built for the challenges of low breadth and complex signal mapping. In the first example above, we demonstrate that forecasting a low breadth global factor can be improved by including a broader swath of data with exposure to the same latent factor. In the second example, we take advantage of ML techniques, creating synthetic breadth at the point of interest level, before aggregating to macro factors — harnessing fragmented big data and applying it to top-down views. Finally, we demonstrate that the choice in learners can lead to material differences in explanatory power when it comes to low-breadth systematic investment problems. These innovations demonstrate how modern machine learning methods, when tailored to macro’s structural characteristics, may unlock new alpha sources and bring greater precision to systematic macro research.
Authors bio

Raffaele Savi
Global Head of Systematic – BlackRock

Philip Green
Head of Global Tactical Asset Allocation Team, Multi-Asset Strategies & Solutions

Michael Pensky, CFA
Deputy CIO, Portfolio Manager, Global Tactical Asset Allocation

Stephanie Lee
Co-lead Systematic Macro, Portfolio Manager, BlackRock Systematic

Ron Kahn, PhD
Global Head of Systematic Investment Research

Michael Pyle, CFA
Deputy Head of the Portfolio Management Group

Thomas Logan, CFA
Macro Researcher, BlackRock Systematic
Hedge funds at BlackRock
At BlackRock, we empower our hedge fund investors to operate seamlessly at scale. We harness comprehensive expertise, global reach, and proprietary technology as we seek to deliver solutions across geographies, asset classes, and investment styles.
Portable alpha strategies
Explore how portable alpha strategies can potentially increase returns by separating the beta and alpha components of a portfolio.
Macro Matters: Global hedge fund allocations
Macro volatility has returned to markets. Discover why many investors are reassessing their portfolios, with a particular focus on idiosyncratic return streams